
Clustering (군집화)
이번 포스팅에서는 Unsupervised learning(비지도 학습) 중 하나인 Clustering (군집화)를 정리해보고자 합니다
Unsupervised learning
먼저 비지도학습이 뭔지 정리해봅시다.
학습 데이터에 대해 label이 주어지는 경우도 있지만, 그렇지 못한 경우도 있습니다.

예를 들어, 위와 같이 개, 고양이, 아기 사진이 있다고 할 때, 우리는 각 이미지의 유사한 정도를 바탕으로 몇 개 그룹으로 나눌 수 있습니다.
몇 개 그룹으로 나누는 과정을 Clustering (군집화)라고 합니다.
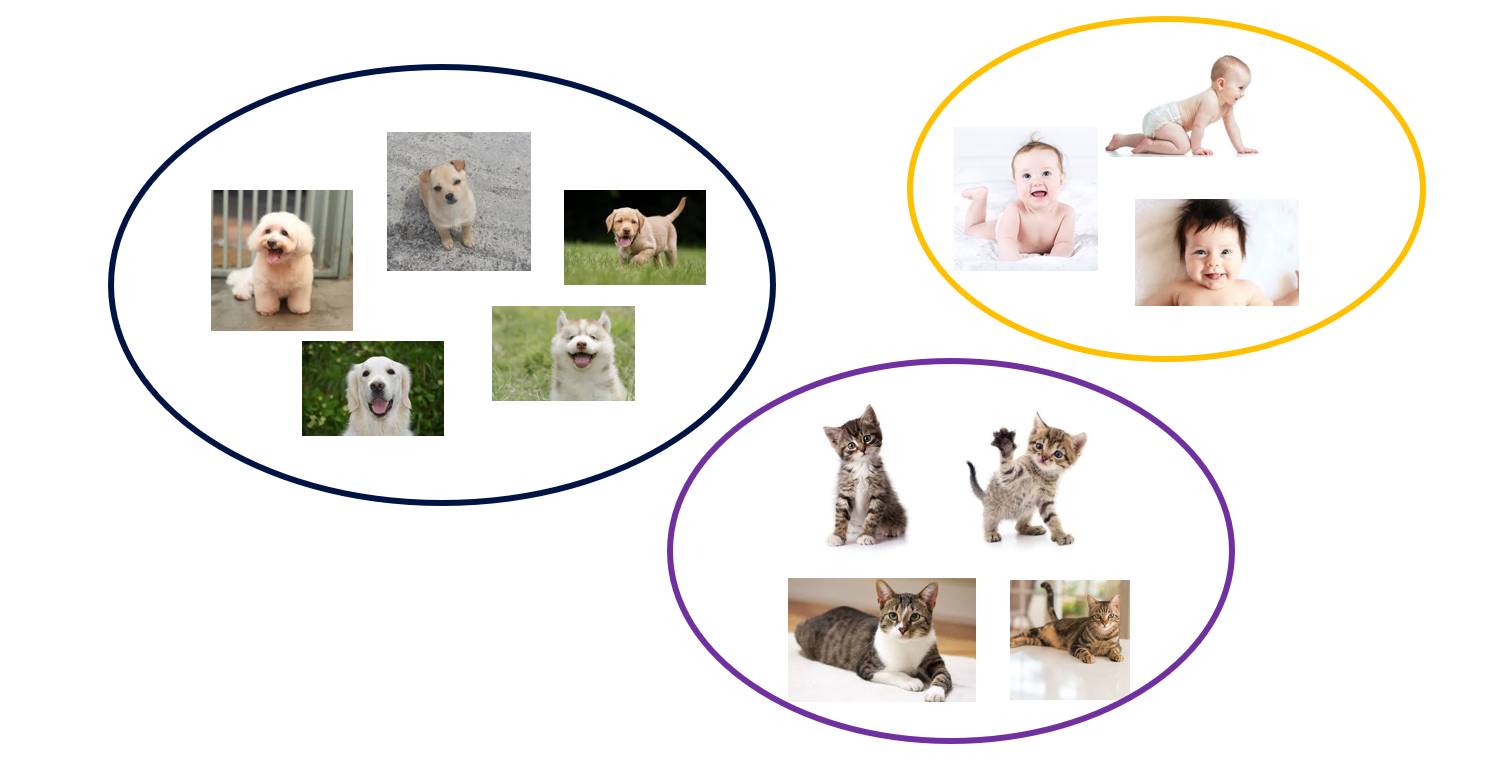
위와 같이 개, 고양이, 아기. 3 개 그룹으로 나눌 수도 있고,

누군가는 사람 대 반려동물 정도로 그룹화를 할 수도 있습니다. 즉, 비지도학습에서는 완벽한 정답이 존재하지 않습니다.
Clustering

비지도학습의 대표적인 예인 Clustering은 주어진 데이터를 몇 개 그룹 (Cluster)로 분리합니다.
이 때 Cluster간 데이터의 분산은 최대화시키고, Cluster 내 데이터의 분산은 최소화시키는 방향으로 학습합니다.
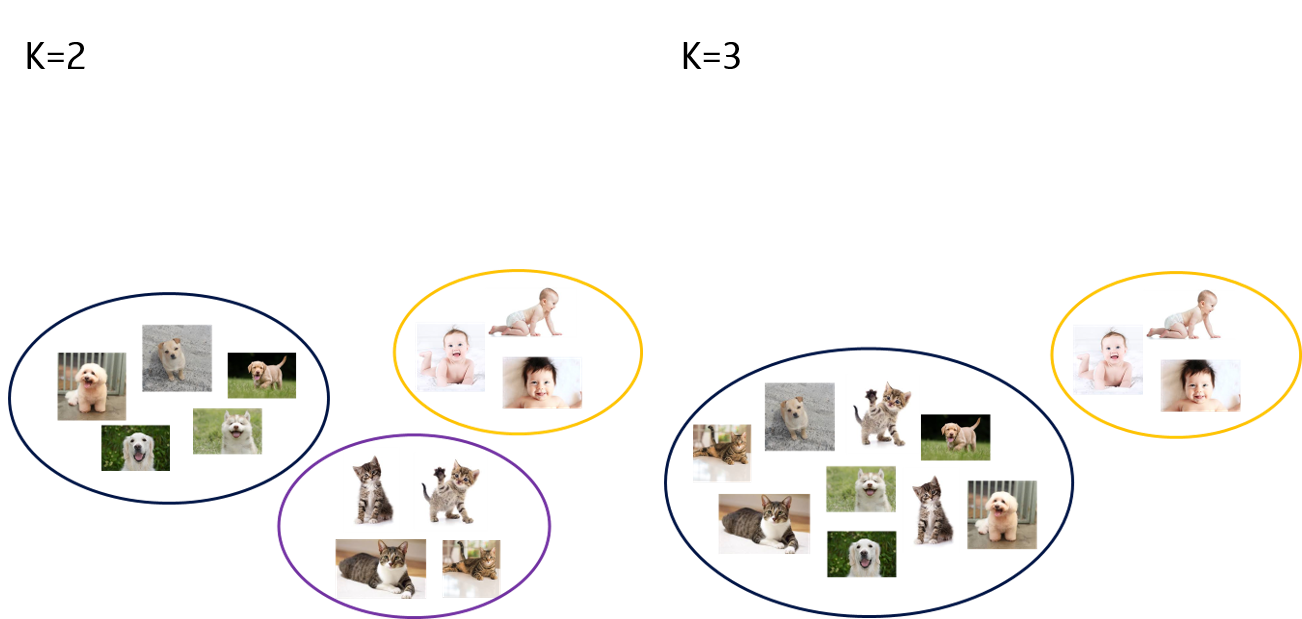
그렇다면 적절한 그룹의 수 \(k\)는 어떻게 정할까요?
Evaluation metrics
분류 모델에 사용되는 지표와 달리, Clustering에 사용되는 평가 지표가 별도로 존재합니다.

이 지표들은 데이터 간 거리 (Distance)나 클러스터의 직경 (Diameter) 또는 분산 (Variance)를 이용합니다.
Dunn index
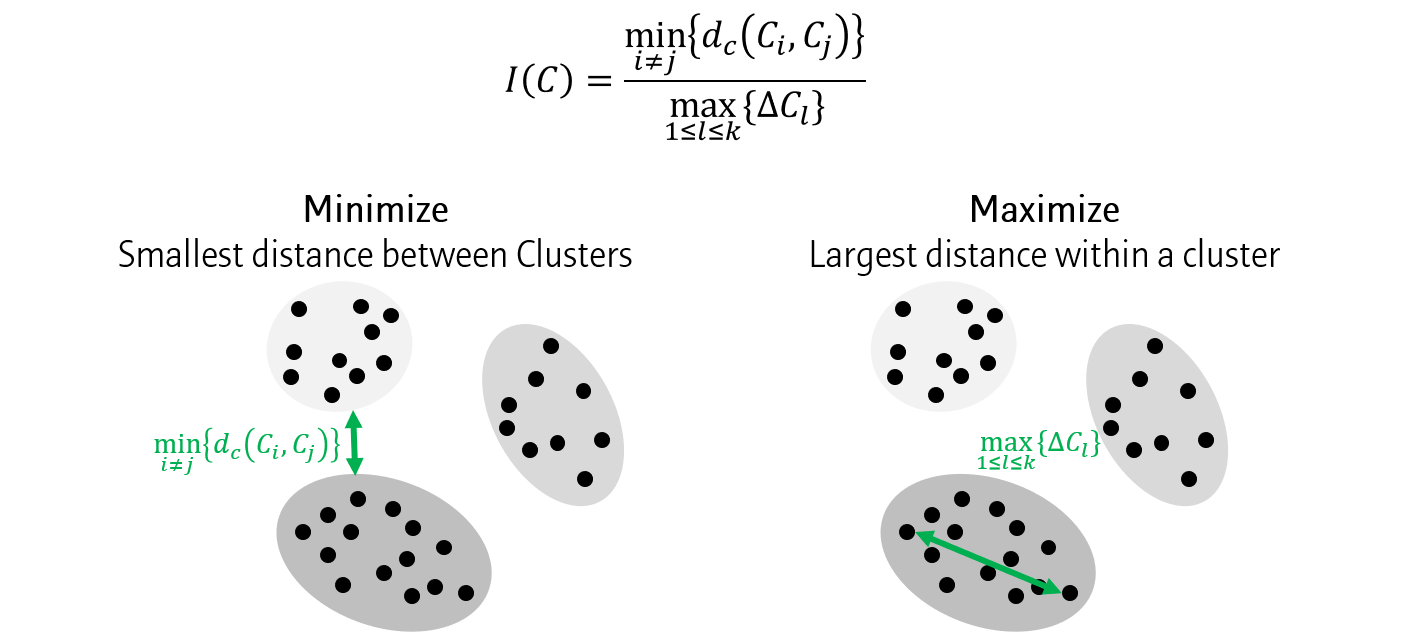
가장 먼저 Dunn index는 클러스터간 거리 중 최소값과 클러스터내 거리 중 최대값의 비율로 나타냅니다.
Silhouette
Silhouette은 Dunn index보다 살짝 복잡합니다.
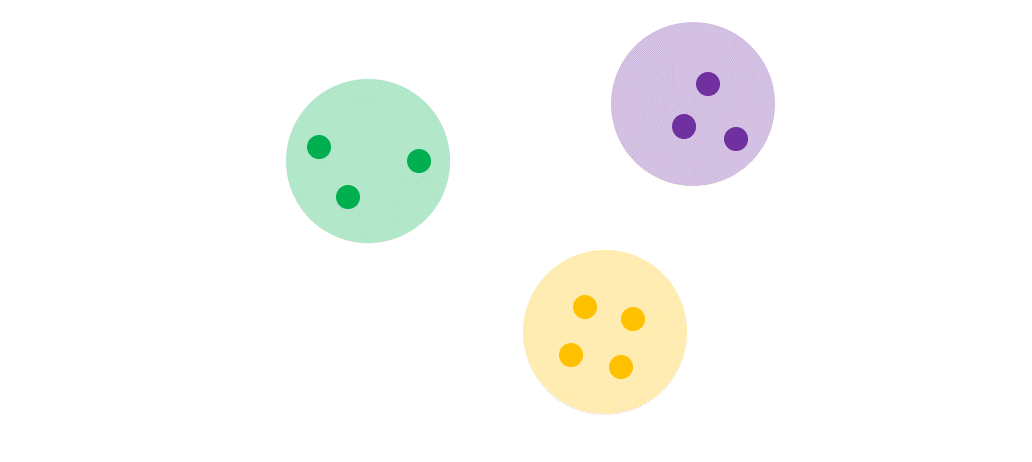
위와 같이 데이터를 군집화했다고 가정해봅시다.
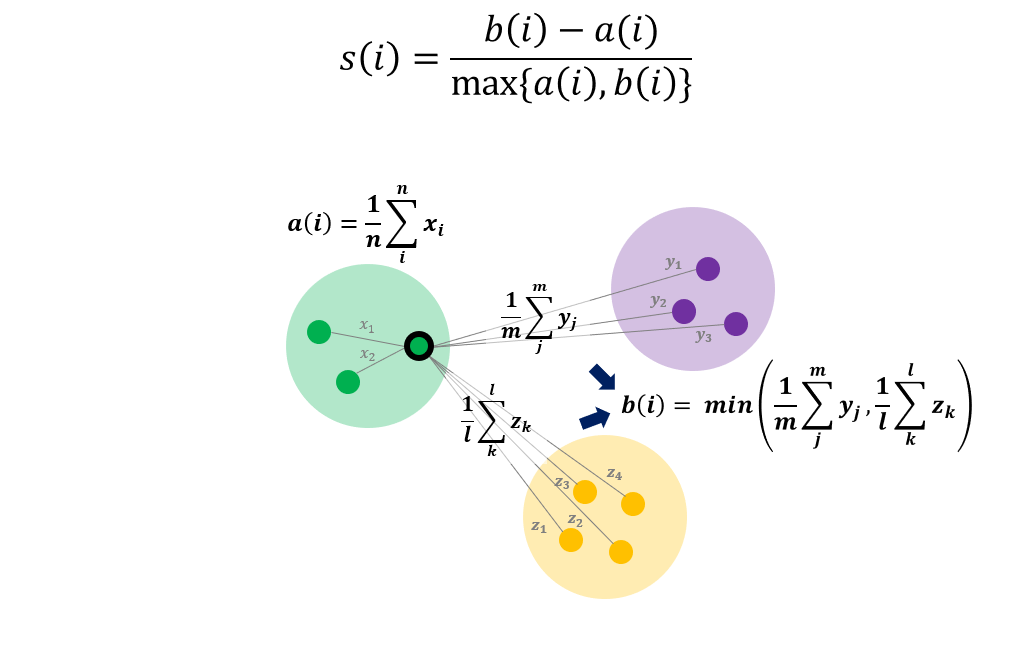
Silhouette 지표는 \(\frac{b(i)-a(i)}{max{(a(i), b(i))}}\)으로 나타냅니다.
- \(a(i)\): 클러스터 내 거리의 평균값
- \(b(i)\): 클러스터 간 거리의 평균값 중 최소값

Silhouette \(s(i)\)는 -1부터 1까지의 값을 갖습니다.
Worst case를 먼저 살펴봅시다. 클러스터를 구분할 수 없을 정도로 군집화가 안 됐을 때는, 클러스터간 거리가 모두 0이 되기 때문에, \(b(i)=0\)이 됩니다. 따라서 \(s(i)=-1\)의 값을 갖습니다.
반면 Best case의 경우, 각 클러스터 내 모든 점들이 한 점에 모여있는 상태에서 클러스터 내 거리가 0이 되기 때문에 \(a(i)=0\)이 됩니다. 따라서 \(s(i)=1\)의 값을 갖습니다.
Types of clustering
Clustering 방법을 몇 가지로 분류할 수 있습니다.
Hard VS Soft clustering

각 데이터가 한 cluster에만 속하는 경우를 Hard clustering이라고 하며, 여러 cluster에 속하는 경우를 Soft clustering이라고 합니다.
Hard clustering의 예로는 K-means clustering과 Hierarchical clustering이, Soft clustering의 예로는 Fuzzy clustering이 대표적입니다.
Partitional VS Hierarchical clustering

또 다른 분류로 Partitional 과 Hierarchical clustering으로 나눌 수 있습니다.
Partitional clustering은 모든 데이터를 한번에 분류하는 방법이고, Hierarchical clustering은 가까운 데이터부터 단계적으로 분류해나가는 방법입니다.
Partitional clustering의 예로는 K-means clustering이 있으며, Hiearchical clustering는 그 이름 자체가 방법입니다.
다음 포스팅에서는 대표적인 Clustering 방법이자 Hard clustering, Partitional clustering의 예시인 K-means clustering을 정리해보고자 합니다
다음 포스팅: K-means clustering
Leave a comment